
This is the first in a series of 3 blog posts that serialize a white paper on the use of Artificial Intelligence and Mathematical Optimization in business and public sector organizations.
While the white paper goes a little deeper, the blog posts follow the same structure to summarize:
- where Machine Learning (ML) as a generalization of AI has found its place in process automation and decision support, and reasons why many potential applications have been slower to see value from ML
- what Mathematical Optimization (MO) does in comparison with ML
- how MO and ML can work together in hybrid solutions that offer more value than the sum of their parts.
In this blog post we describe some fundamental characteristics of Machine Learning as needed to highlight some of the challenges it faces and understand why it succeeds where it does.
Machine Learning use cases
Now that we have used the term Artificial Intelligence enough to optimize search engine results, this blog post will favor the term “Machine Learning” (ML), as it means almost the same thing as AI but makes us think of real-world applications: more forecasting and process automation, less making video games realistic and talking to Alexa.
"In the Nordic countries, the first organizations to realize the benefits of AI/ML are those with AI close to the core business (part of product/service). From a group of organizations surveyed this year who use AI/ML anywhere, 73% use it as part of a product/service (74% Finland) whereas 24% use it in back-office processes (16% Finland)."
Intuitively for any product more things are happening behind the scenes in IT, human and business processes than in the product itself. For example, a wearable device that classifies your health or predicts your future based on heart rate fluctuations makes obvious use of ML but is the tip of an organizational iceberg wherein countless processes must first ensure success in design, manufacturing, quality assurance, distribution, sales, recruitment, and compliance to mention a few.
Moreover, there are more organizations whose products do not (yet) have an obvious place for ML, but whose behind-the-scenes processes are frustrated by inefficiencies and subjectivity in human decision-making.
Let’s explore why, given higher demand for ML behind-the-scenes, such processes are slower to adopt the technology.
Characteristics of Machine Learning
Machine learning is used to predict expected values, classify things into expected groups and detect where or when something occurs. We will just use the term prediction, as classification and detection models are still predicting (not knowing for sure) a group membership or position.
"To make predictions ML is first “trained” to learn what properties are typical of certain entities. For this to be of any use, the property sought is something that we did not know about the entity when the data were collected, but we found out after the fact. In this way, when given the known data for new example of an entity, we can predict the unknown property."
For example, as part of its digital transformation a company may gather an unprecedented volume of data on transactions such as credit card payments or online insurance claims. We may predict the likelihood that a transaction is fraudulent, given enough details of the products, people, events, and accounts involved, by using an ML model that has been shown the same details of previous transactions that are known to be fraudulent (and some that are known to be OK).
The main components of an ML model are shown as a workflow in FIGURE 1.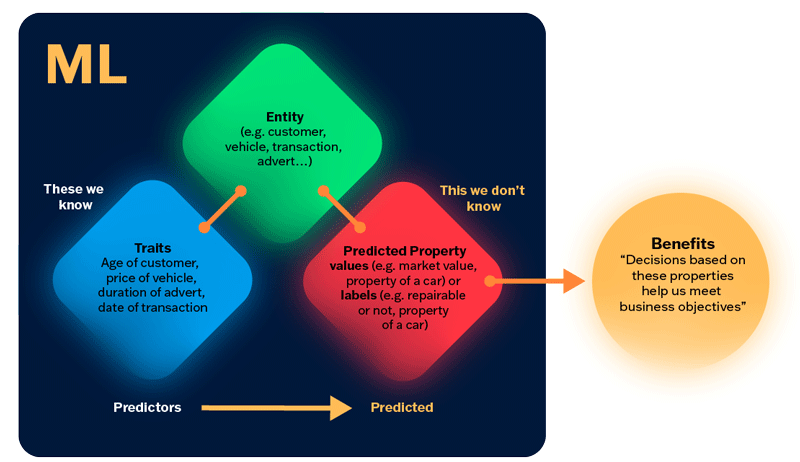
FIGURE 1 – Components of a ML model and its outcomes.
The outcome, a prediction, has no value on its own and to realize the benefits of ML we must put the predictions to some use. Continuing with the fraud example, predictions from ML can be used in automatic decision-making (blocking the account of a credit card suspected of being used for fraud) or recommendation engines (recommending the most suspicious cases for inspection by humans).
TABLE 1 describes typical in-product and behind-the-scenes use cases of ML along with characteristics of the type of business problems that ML is suited to solve.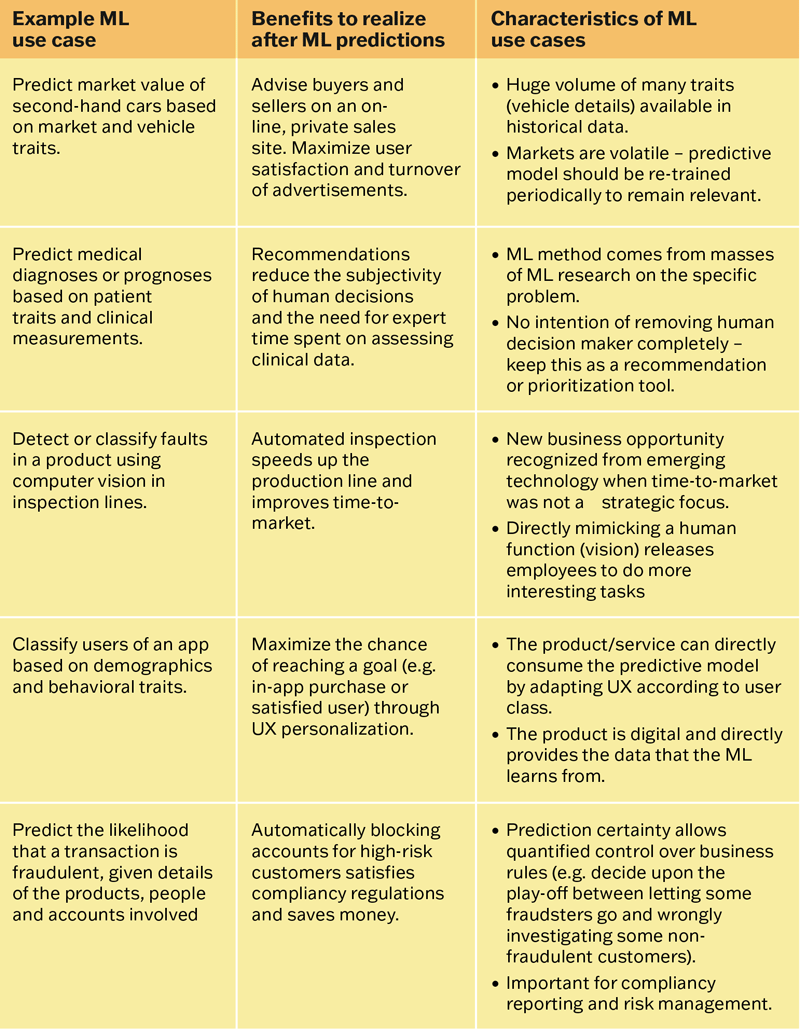
TABLE 1 – Examples and characteristics of ML use cases.
One of the most important characteristics of ML use cases is that the model needs to learn again and again from fresh data, as facts and relationships change over time. Overlooking this need is a key reason why ML has not convinced many decision-makers: a model that performs well at first may be giving poor predictions in later months because it has learned from old data and is still ‘living in the past’. There are other bottlenecks too as we will find out next.
Bottlenecks of Machine Learning
Let’s look at three reasons why ML has been slow to meet its expectations. The first and simplest is that expectations have been too high in the past. The success of Machine Learning is very well described by Gartner’s “Hype Cycle of Emerging Technologies”, which holds true for ML (FIGURE 2) as well as other technologies such as Internet of Things (IoT), Cloud Computing and Blockchain Business.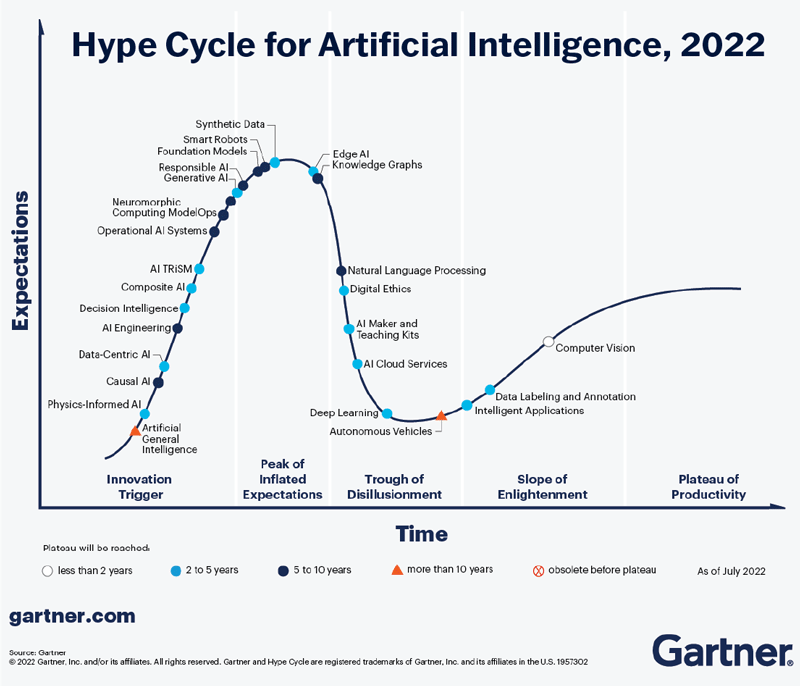
FIGURE 2 – Gartner’s Hype Cycle for Artificial Intelligence
Machine Learning suffered from inflated expectations in the early stages, as experiments and PoCs were pursued with little thought about how to realize the benefits. This phenomenon is well summarized by Tonia Sideri of Novo Nordisk who notes that all too often Data Scientists find themselves “working on projects that should have been stopped a long time ago” because the outcomes will have little or only theoretical value and never be used. The perceived waste of time may have left business cynical toward ML.
For a while, a large bulk of efforts to rescue ML has focused on cloud-based ML services to remove technological bottlenecks that kept ML results in PowerPoint files, unable to release predictions in the real world through integration with existing IT.
"In Gartner’s latest picture (FIGURE 2), we are currently on the “slope of enlightenment”, where expectations are rising again, but with more caution and driven by more visible successes in niche areas such as computer vision and natural language processing."
These niche areas are not relevant to many pain points in a typical organization (few businesses can increase productivity by telling cats from dogs in photos) but moreover, the data coming from complex combinations of back-end systems are not as clean and meaningful as image or audio data where all the information was collected by a single instrument for the pre-defined purpose of being looked at or listened to.
This brings us to the second bottleneck facing ML: being sure that there is value in the use case. To avoid going too far into a dead-end project (and to quote Tonia Sideri) we need to "... start new projects with a 'data to wisdom sprint'.
"This is a hackathon where we work together with our business colleagues for 2 weeks, to see what we find from the data based on certain hypotheses. At the end of the 2 weeks we ask: is there signal in the noise? Are the data good enough? Do we have the necessary technology to scale up further? Is there any business value?"
Even if we can expect good enough data and have a way to plug-in our ML predictions behind the scenes in automatic or recommendation processes, the kind of ‘data to wisdom’ exercise described above may still reject some use cases because they do not stand up to a reality-check.
This brings us to the third ML bottleneck: We are more reluctant to automate decisions based on predictions than facts, not just because of the uncertainty or inaccuracy of predictions, but also:
- A decision based on one thing predicted, will also affect other things not predicted. For example, to reduce the expected number of “money back” requests for a product, we could predict the rate for different age groups, and make the decision to exclude the most unsatisfied age group from future sales. However, we would need to perform consequence-analysis on the effect this has on overall profits or brand perception. Taking these factors into account simultaneously becomes too complex and calls for a more principled approach.
- We may want to make decisions for very many entities at the same time, e.g. individual shift allocations for hundreds of shift-workers. For these decisions to be influenced by ML predictions we would either need to train a model on many examples of each combination of people & shifts (there would be billions) or train a model per worker, each of which is blind to the effect of all other worker’s shift allocation and therefore useless.
- Decisions often need to observe business rules, or meet external factors such as law, GDPR, ethics, physical limitations or business strategy. These are what we call “constraints”. Despite not sounding too sexy, constraints are actually a GOOD thing, as they place theoretical results into a more practical, real-world context.
So where do we go from here?
"Machine Learning is a valuable tool with many use cases yet to be realised in removing subjectivity and effort from behind the scenes processes. A big step toward putting ML into production comes from the use of predictions in recommendation or ranking steps within an otherwise human process."
Table 1 mentions this role of ML in the medical field, where human expertise are never likely to be fully replaced by automation, but in other examples such as fraud detection there may be human investigation functions in an organization whose work can be significantly streamlined without full automation of hard actions like freezing a customer account, and by keeping the human “in the loop” we satisfy various requirements of ethical and legal obligations toward society.
As well as striking the balance between automated and augmented decision making, we see a need to tightly couple the output of ML (predictions) with decisions themselves. It is not always clear what ML predictions are telling us to do in practice, given the desired end-game of reaching our business goals or societal impact.
The next blog post in this series will re-visit these challenges in the context of Mathematical Optimization (MO). Mathematical optimization is closely related to ML and shares some of the challenges while directly addressing others, in particular the reluctancies above.
Read the next blog post or download our whitepaper to get access to the full content.
